Starting with VAST Platform 2024 (13.0.0), we introduced Unicode support in our Database Management (DBM) libraries. Unicode support works as an opt-in feature that can be enabled or disabled per connection, per database platform, or globally for all connections.
Previously, if you stored text in a database that supported Unicode — by storing strings encoded in some form of UTF — you might have been limited by the code page used by the database driver and/or the code page used by your VAST application. This limitation occurs because the set of characters that can be represented by the code page is significantly smaller than the virtually infinite set of characters that can be represented by Unicode.
With this new feature, you can overcome this limitation by taking advantage of VAST's existing Unicode support.

Various database drivers and their corresponding VAST classes will convert bytes received by the driver into instances of String using the active codepage used by VAST. When storing String instances, it will do the same in the opposite direction, taking the single or double-byte characters and sending them as is to the database. This opens the door to, and often causes, problems when an application attempts to read or write text to or from a database when there is a codepage mismatch between the client and server that isn't automatically handled by the DB driver.
If you enable Unicode on a database connection (we'll show you how to do this later), instead of retrieving String instances from the database, you will retrieve instances of UnicodeString. When you insert or update text fields in a database table, the UnicodeString will be encoded as UTF (usually UTF-8). You can still send codepage-dependent String instances for storage, as they will first be converted to UnicodeString using the active codepage of your VAST application (or development environment).

Unicode support can be enabled on a per-connection basis by sending #enableUnicode (a shorthand for #unicodeEnabled: true) to the connection.
You can also enable (or disable) Unicode support at the Database Manager level (e.g. for all your Oracle connections), which will cause all new connections created by that manager to inherit the value defined in the manager.
And if you want to enable Unicode support globally for all managers (and by extension: connections), you can do AbtDbmSystem unicodeEnabled: true.
As you might have guessed, if you don't explicitly enable or disable Unicode on connection, there is a resolution path that goes like this AbtDatabaseConnection > AbtDatabaseManager > AbtDbmSystem. You can enable or disable it at any level.
You can also specify the UTF encoding to use in each connection when Unicode is enabled, by default it will be UTF-8 (by means of using VAST's Utf8 encoding class).
With all database connections, you can enable or disable Unicode support after the connection is created, and even toggle support during the lifetime of the connection (although it's not recommended… and likely not useful).
But ODBC is different, because ODBC uses a different class for Unicode connections (AbtOdbcUnicodeDatabaseConnection), which uses different functions and a fixed encoding (UTF-16) when making calls to the API.
Thus, you can enable or disable Unicode support at the AbtOdbcDatabaseManager level, and it will create regular AbtOdbcDatabaseConnection instances or AbtOdbCUnicodeDatabaseConnection instances according to the setting defined at the manager level. Note that once the connection is created, you can change the manager-level setting to instantiate a non-Unicode enabled ODBC connection.
Some database drivers don't use Unicode encoding by default, especially for Windows applications that are codepage dependent for the most part, so here's a small list of how to do that for some of the platforms that require it.
Oracle database versions 10.x and later require that your application (and thus VAST) run with the NLS_LANG environment variable specifying UTF-8 encoding.
NLS_LANG=_.AL32UTF8
NLS_LANG=SPANISH_SPAIN.AL32UTF8IBM DB2 also requires that your application run with the DB2CODEPAGE environment variable specifying UTF-8 encoding.
# For UTF-8
DB2CODEPAGE=1208The only requirement for using Unicode support with ODBC connections is that the ODBC driver supports Unicode. Not all drivers support Unicode by default, and some clearly specify whether it's ANSI (codepage dependent) or UNICODE.
This is because using Unicode over ODBC requires a number of different API functions that not all drivers provide.
All UnicodeString instances passed as arguments to these Unicode API functions will be encoded as UTF-16, as this is the only encoding that such functions will accept. This may add a bit of overhead, as UnicodeString's internal storage is validated UTF-8, there will be an additional conversion due to the required re-encoding. The encoding is done at the VM level and is blazing fast so you probably won't notice it, but your mileage may vary.
Most PostgreSQL databases use UTF-8 by default for both storage and clients. The client encoding is also set at the server level. So if you need to change this, contact your DBA.
SQLite uses UTF-8 for all the TEXT storage, so you don't need anything special. And if you do, you'll likely find yourself recompiling it from its sources.
When executing a statement with bound parameters, you usually pass a dictionary whose keys are strings, but since UnicodeString and String have different hashing values, there could be problems when passing a statement that is String and keys that are UnicodeString, or vice versa.
To overcome this situation, we introduced the StringDictionary class, which allows you to use String and UnicodeString in the same dictionary, using a special hashing for the keys (by converting them to UTF-8 encoded bytes and hashing them).
So if you are using bound parameters along with Unicode support, we recommend using StringDictionary whenever possible.
Note: All code samples below assume you're executing them in a workspace with UTF-8 encoding.
This example enables Unicode support at the manager level so that new connections inherit this value, uses a regular string for the statement, and passes the binding values using StringDictionary.
"Enable Unicode at the manager level."
AbtOracle10DatabaseManager unicodeEnabled: true.
"Specify login and connect"
logonSpec := AbtDatabaseLogonSpec
id: 'username'
password: 'password'
server: 'localhost:1521/xe'.
connection := conSpec
connectUsingAlias: 'oracle_xe194'
logonSpec: logonSpec
ifError: conSpec defaultErrorBlock.
connection unicodeEnabled. "true"
connection unicodeEncoding. "Utf8"
result := connection
executeQuerySpec: (AbtQuerySpec new statement: 'UPDATE YOURTABLE SET FIELD = :FIELDVALUE WHERE ID = :ID')
withValues: (StringDictionary
with: 'ID' -> 'sample1'
with: 'FIELDVALUE' -> 'пустынных' utf8AsUnicodeString )
ifError: [ :err | err ].It could be the case that you use the same database manager to connect to different databases without using Unicode, but there is one database for which you want to enable. You can do that easily, by enabling it at the connection level.
conSpec := AbtDatabaseConnectionSpec
forDbmClass: #AbtPostgreSQLDatabaseManager
databaseName: 'glorptest'.
logonSpec := AbtDatabaseLogonSpec
id: 'glorptest'
password: 'password'
server: ''.
connection := (conSpec connectUsingAlias: 'PG' logonSpec: logonSpec).
"Enable Unicode just for this connection."
connection enableUnicode.
result := connection
resultTableFromQuerySpec:
(AbtQuerySpec new statement: 'SHOW CLIENT_ENCODING' )
ifError: [ :err | err ].
result asArrayNational datatypes in databases, such as NCHAR and NVARCHAR, are specialized datatypes designed to store text data in a way that supports international character sets. Unlike their counterparts CHAR and VARCHAR, which were traditionally used to store character data that was codepage-dependent, NCHAR and NVARCHAR are specifically designed to handle Unicode data. This capability makes them ideal for databases that need to store information in multiple languages, allowing for "secondary" encoding in codepage-dependent databases.
When these datatypes were first introduced, they used the UCS-2 encoding, which allowed a fixed-width representation of characters, but was limited to a range of characters within the Basic Multilingual Plane (BMP). This limitation meant that UCS-2 could not represent characters outside of this plane, such as many historical scripts or recent additions to the Unicode standard. However, as the need for a more comprehensive character set representation grew, modern implementations of NCHAR and NVARCHAR moved to using UTF-16, allowing databases to store virtually any character from any writing system in use today, providing a more versatile and comprehensive environment for global data storage and retrieval.
What this means for VAST is that these field types will always use UTF-16 as their encoding, regardless of the encoding configured for the connection (typically UTF-8).
The field length for string datatypes (such as CHAR, VARCHAR, etc.) has historically been defined assuming that one byte equals one character, which of course has major limitations when trying to store international text where a single character may be encoded as multiple bytes, resulting in truncation issues.
So instead of defining the length of these strings in terms of bytes (byte semantics), character semantics allows the length to be defined in terms of characters. In character semantics, the length of a string is measured by the number of characters it contains, regardless of the number of bytes each character occupies.
But for most database engines, a "character" (in character semantics) means a "codepoint" in Unicode terms, which in VAST is mapped to a UnicodeScalar. In VAST, a UnicodeScalar can be combined with others to form a multi-scalar Grapheme, which in turn can be combined with other graphemes to form a UnicodeString.
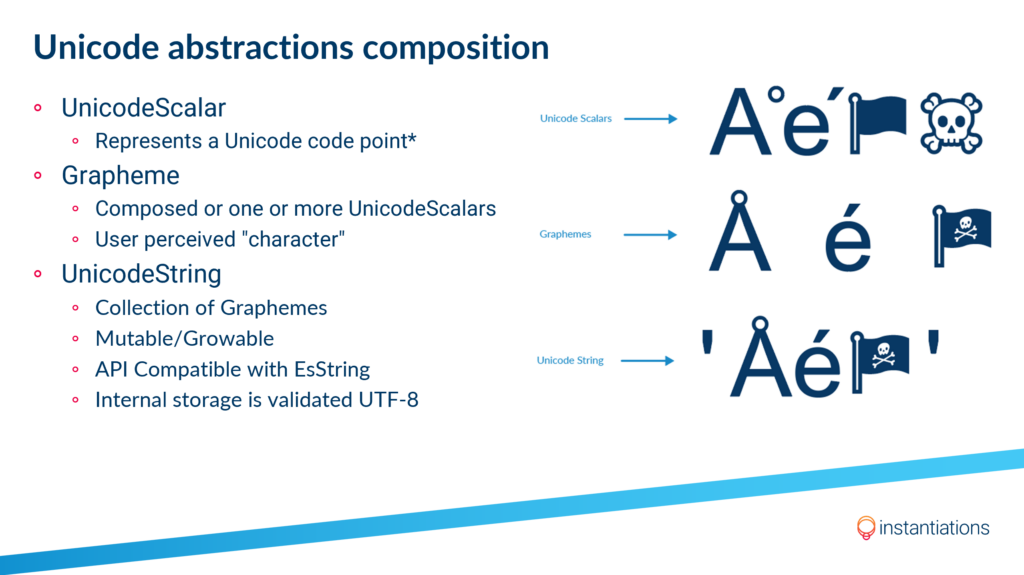
Some database engines only support character semantics, others have it as a database setting, and others allow you to specify it on a per-column basis using something like VARCHAR(20 BYTE) or VARCHAR(20 CHAR). VAST will understand these differences and map them transparently when reading and writing UnicodeString to and from these fields.
Our Unicode support doesn't stop at the base layer of database management, and we have also added support to our featured ORM, the well-known GLORP framework.
Enabling Unicode support in GLORP is quite simple and the only requirement to use Unicode is to enable it at the DBM manager level, i.e. you enable it in the AbtDatabaseManager subclass for ODBC, Oracle, DB2, PostgreSQL or SQLite. For example:
"Enables Unicode Support"
session accessor unicodeEnabled: true.
"Saves persons with names in different languages"
session save: (GlorpPerson named: 'Ἀπόλλων' utf8AsUnicodeString).
session save: (GlorpPerson named: 'Андрей' utf8AsUnicodeString).
session save: (GlorpPerson named: '老子' utf8AsUnicodeString).
"Reads using an expression block that involves a UnicodeString"
person := session readOneOf: GlorpPerson where: [:each | each name ='Ἀπόλλων' utf8AsUnicodeString ].
person a GlorpPerson(3806478,'Ἀπόλλων')This is because creating new connections in GLORP is done in a way that doesn't allow us to add a custom configuration block. We could have modified the code to behave similarly to the DBM classes, but even as we maintain a fork of this open-source project, we try to keep the codebase as close as possible to that of other dialects to facilitate porting and merging of new features in both directions.
The introduction of Unicode support in VAST 13.0.0 is a significant step in our roadmap to support Unicode across all of our libraries. Designed as an opt-in option, this new feature provides users with the much-needed ability to efficiently handle Unicode text across multiple database platforms. With this update, VAST's Database Management (DBM) libraries have been significantly enhanced to overcome the limitations previously imposed by limited code pages.
